Linux学习之旅3——数据流与进程(上)
一.数据处理
-
grep 命令:筛选数据(Globally search a Regular Expression and Print)
1
grep text file
上述命令中,text为要搜索的文本,file为要搜索的文件
1
2# 搜索.bashrc文件中的alias文本,显示所有包含alias的行
grep alias .bashrc参数介绍
-
-i 忽略大小写
1
grep -i alias .bashrc
-
-n 显示行号
1
grep -n alias .bashrc
-
-v 搜索文本不存在的行
1
grep -v alias .bashrc
-
-r 在子目录和文件中查找
1
2grep -r "Hello World!" folder/
# 最后的参数必须是directory,可以没有斜杠 -
-E 可配合正则表达式搜索文本
1
2grep -E ^alias .bashrc
# 若此处忘记正则表达式语法,请看下处链接
-
-
sort 命令:为文件排序
1
2# 按英文首字母排序file.txt文件内容(不会改变原文件内容)
sort file.txt参数介绍
-
-o 排序后内容写入新文件(output)
1
sort -o file_sorted.txt file.txt
-
-r 倒序排列(reverse)
1
sort -r file.txt
-
-R 随机排序(random)
1
sort -R file.txt
-
-n 对数字排序
1
sort -n number.txt
-
-
wc 命令:文件的统计(word count)
1
2
3
4wc file.txt
# 输出:
10 9 51 file.txt
# 分别代表行数(换行符数目),单词数,字节数参数介绍
-
-l 统计行数
1
wc -l file.txt
-
-w 统计单词数
1
wc -w file.txt
-
-c 统计字节数
1
wc -c file.txt
-
-m 统计字符数
1
wc -m file.txt
-
-
uniq 命令:删除文件中的重复内容(unique)
1
2# 删除repeat.txt的文件重复内容并输出到unique.txt
uniq repeat.txt unique.txt参数介绍
-
-c 统计重复的行数(count)
1
uniq -c repeat.txt
-
-d 只显示重复行的值(duplicated)
1
uniq -d repeat.txt
-
-
cut 命令:剪切文件的一部分内容
1
2# 根据字符数来剪切(以剪切每一行只保留1-3个字符为例)
cut -c 1-3 file.txt剪切csv文件
1
2
3cut -d , -f 1 mark.csv
# -d(delimiter)分隔符,用于指定csv文件里的分隔符
# -f(field)区域,指定剪切分隔符分隔的哪一块区域
二.流和输出重定向
-
命令的输出有三个去向(终端/文件/其他命令的输入)
-
“>”:重定向到文件(文件不存在则创建,已存在则覆盖)
1
2
3
4
5cut -d , -f 1,3 mark.csv > students.txt
# 注意,若students.txt存在,内容会被覆盖!
cut -d , -f 1,3 mark.csv > /dev/null
# Linux的“黑洞”文件,发送到此文件的数据作废 -
“>>”:重定向到文件末尾(文件不存在则创建)
1
2cut -d , -f 1,3 mark.csv >> students.txt
#将数据追加到students.txt末尾,不覆盖原文件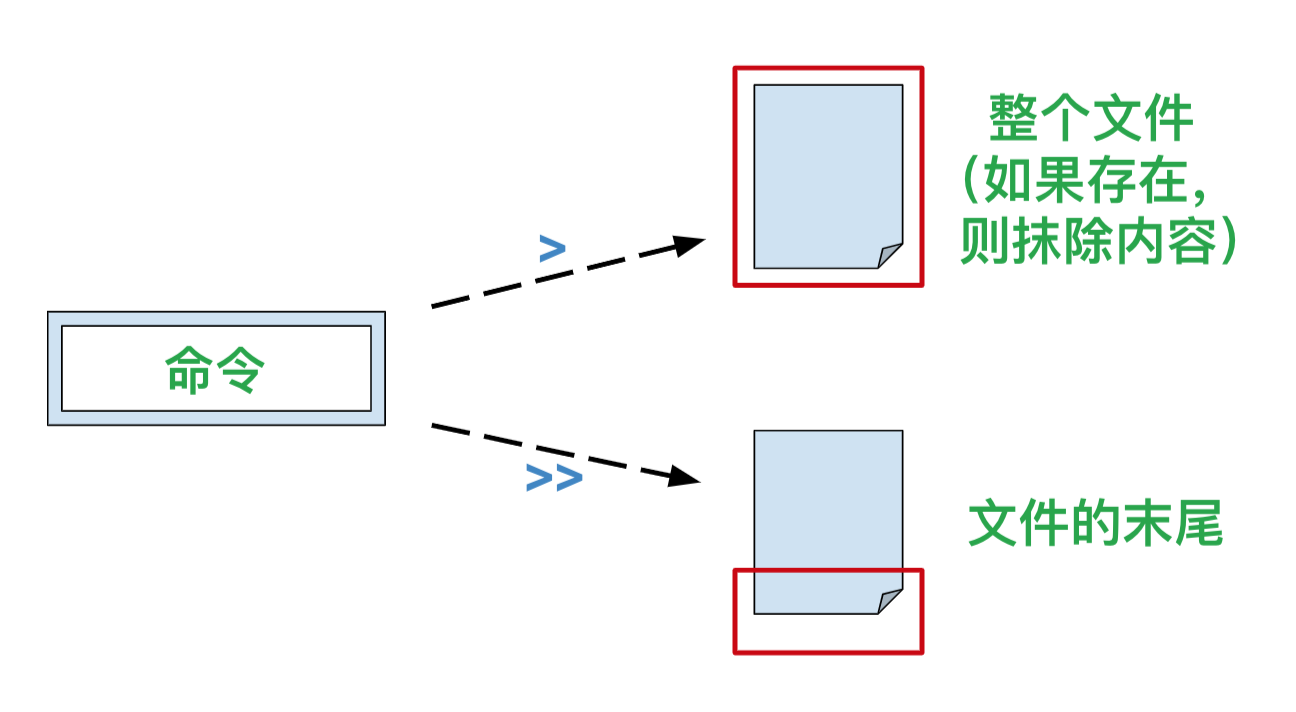
-
重定向错误输出
-
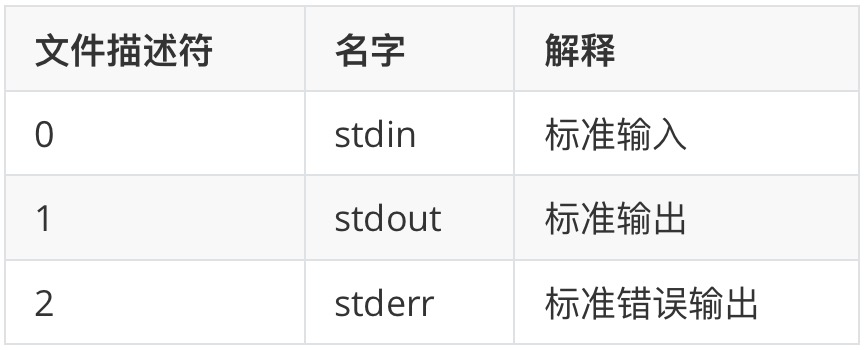
stdin:标准输入
-
stdout:标准输出(终端输出的信息)
-
stderr:标准错误输出(终端输出的错误信息)
-
">“与”>>"只能将标准输出重定向到文件,若要重定向标准错误输出呢?
-
使用"2>"与"2>>"重定向即可
1
2
3
4
5
6cat notExist_file.csv > results.txt 2> errors.log
# 两个重定向,标准输出重定向到results.txt,标准错误输出重定向到errors.log
cat notExist_file.csv > results.txt 2>&1
cat notExist_file.csv >> results.txt 2>&1
# 将标准输出及标准错误输出都重定向到results.txt中,2>&1的组合不变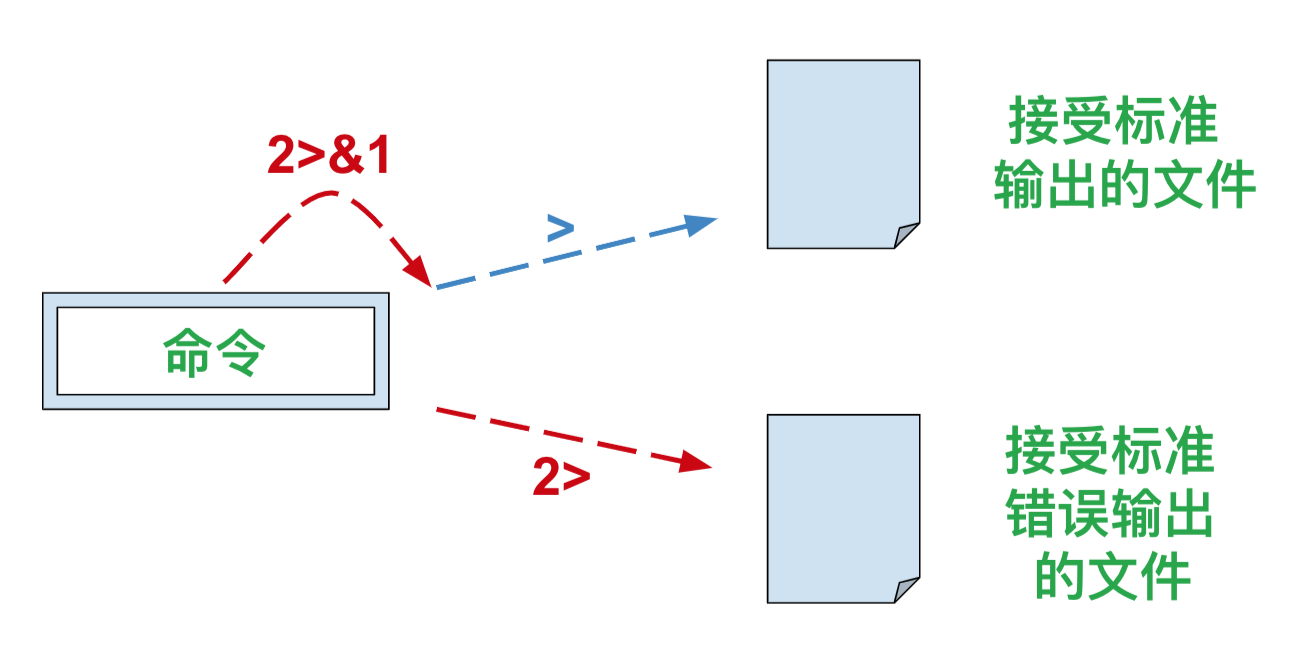
-
三.输入重定向和管道
-
“<“与”<<”:从文件或键盘读取
1
2
3
4
5
6
7
8
9
10
11
12# cat命令负责将内容打印,打开文件并传送内容由Shell完成
cat < file.txt
# cat命令打开文件,并打印文件内容
cat file.txt
# 使用"<<"从键盘输入,最后参数为结束字符串
sort -n << END
wc -m << END
# 与输入重定向组合使用
sort -n << END >> numbers_sorted.txt 2>&1 -
管道(“|”)
1
2
3
4
5# 将一个输出变到另一个文件输入
cut -d , -f 1 mark.csv | sort > sorted_mark.txt
# 举例:输出按大小排序前10的文件名
du | sort -nr | head
下一篇文章推荐:Linux学习之旅4——数据流与进程(下)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 515code-实验室!
打赏
 wechat
wechat alipay
alipay
相关推荐






评论