一. 导学
微服务是分布式架构的一种,就是把服务做拆分。传统单体架构代码容易耦合,大型互联网项目要拆分。把一个独立的项目成为服务,最后形成服务集群,一个业务可能需要用到多个服务。
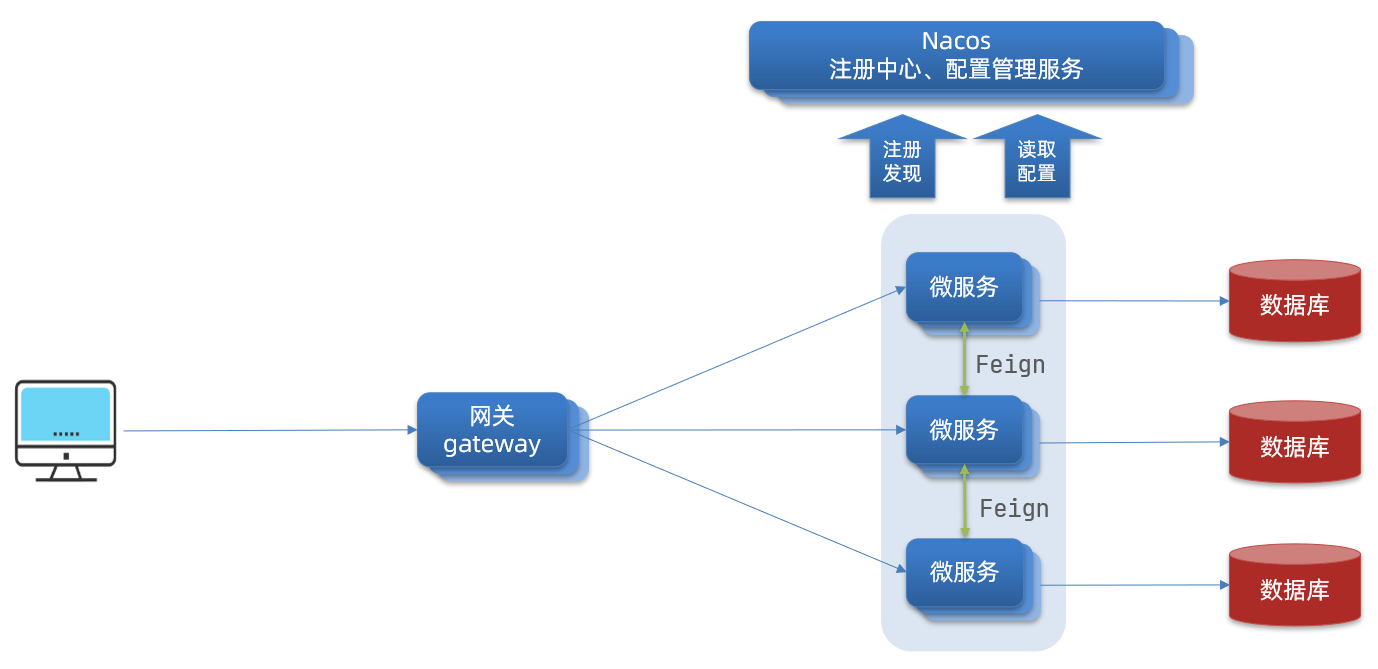
注册中心(拉取或注册服务信息),用以记录服务的IP和端口等服务,服务前往注册中心寻找另外一个服务。
配置中心(拉取配置信息),统一管理整个服务集群的配置文件,实现配置热更新。
服务网关负责对用户身份做校验,并作为请求路由,进行负载均衡。
由于数据库较少,用户数量庞大,还要进行分布式缓存和分布式搜索。
使用消息队列进行异步通信,可以提高并发性能。
学习路线按类可以分为五部分,分别是微服务治理、缓存技术、搜索技术、异步通信技术和DevOps。
二. 认识微服务
单体架构:将业务所有功能集中在一个项目中开发,打成一个包部署。优点是架构简单,部署成本低。缺点是耦合度较高。
分布式架构:根据业务功能对系统进行拆分,每个业务模块独立开发,称为一个服务。优点是耦合度降低,利于服务升级拓展。但是要考虑的问题也会增多:
服务拆分粒度?
服务集群地址如何维护?
服务之间如何实现远程调用?
服务健康状态如何感知?
微服务是一种经过良好架构设计的分布式架构方案,其特征为(高内聚、低耦合):
单一职责:服务拆分粒度更小,每个服务对应一个业务能力,避免重复开发
面向服务:对外暴露业务接口
自治:团队独立、技术独立、数据独立、部署独立
隔离性强:隔离、容错、降级,避免出现级联问题
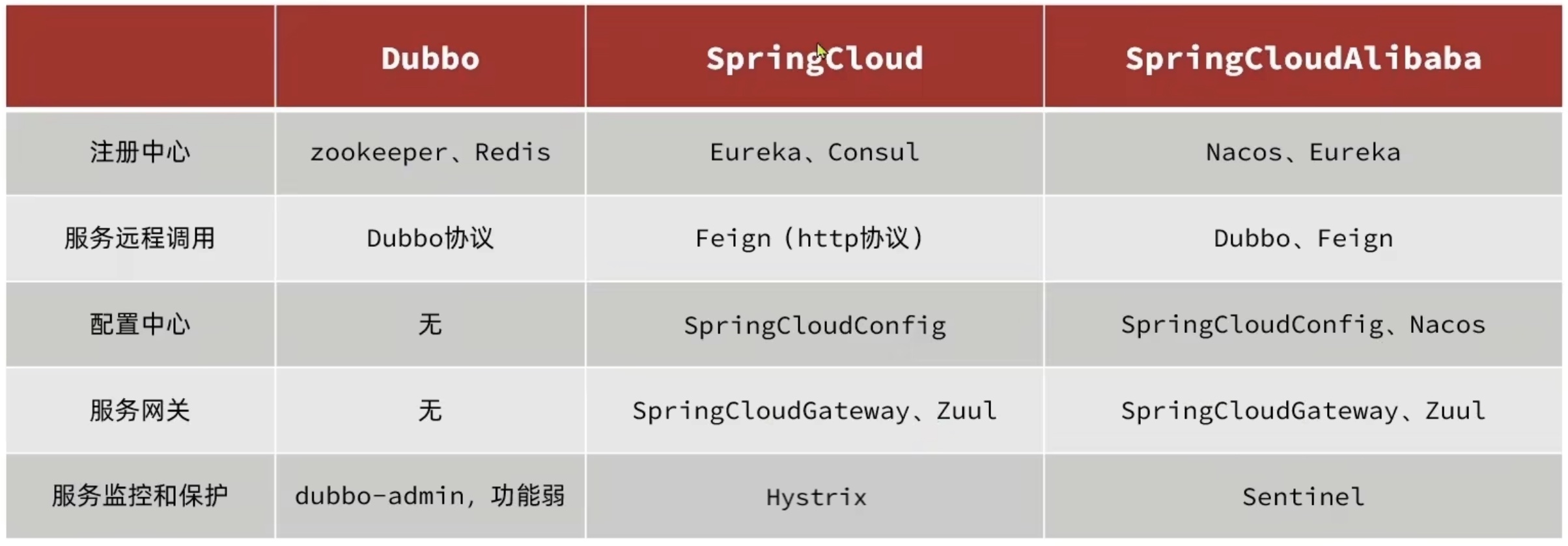
微服务方案需要技术框架落地,知名的框架包括SpringCloud和阿里巴巴Dubbo。
SpringCloudAlibaba提供Dubbo+SpringCloud的接口规范支持。
远程调用
我们希望通过发起HTTP请求调用另一个服务的RestFul Api接口。
注册RestTemplate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @MapperScan("cn.itcast.order.mapper") @SpringBootApplication public class OrderApplication { public static void main (String[] args) { SpringApplication.run(OrderApplication.class, args); } @Bean public RestTemplate restTemplate () { return new RestTemplate (); } }
在业务中进行远程调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private RestTemplate restTemplate; public Order queryOrderById (Long orderId) { Order order = orderMapper.findById(orderId); String url = "http://localhost:8081/user/" + order.getUserId(); User user = restTemplate.getForObject(url, User.class); order.setUser(user); return order; } }
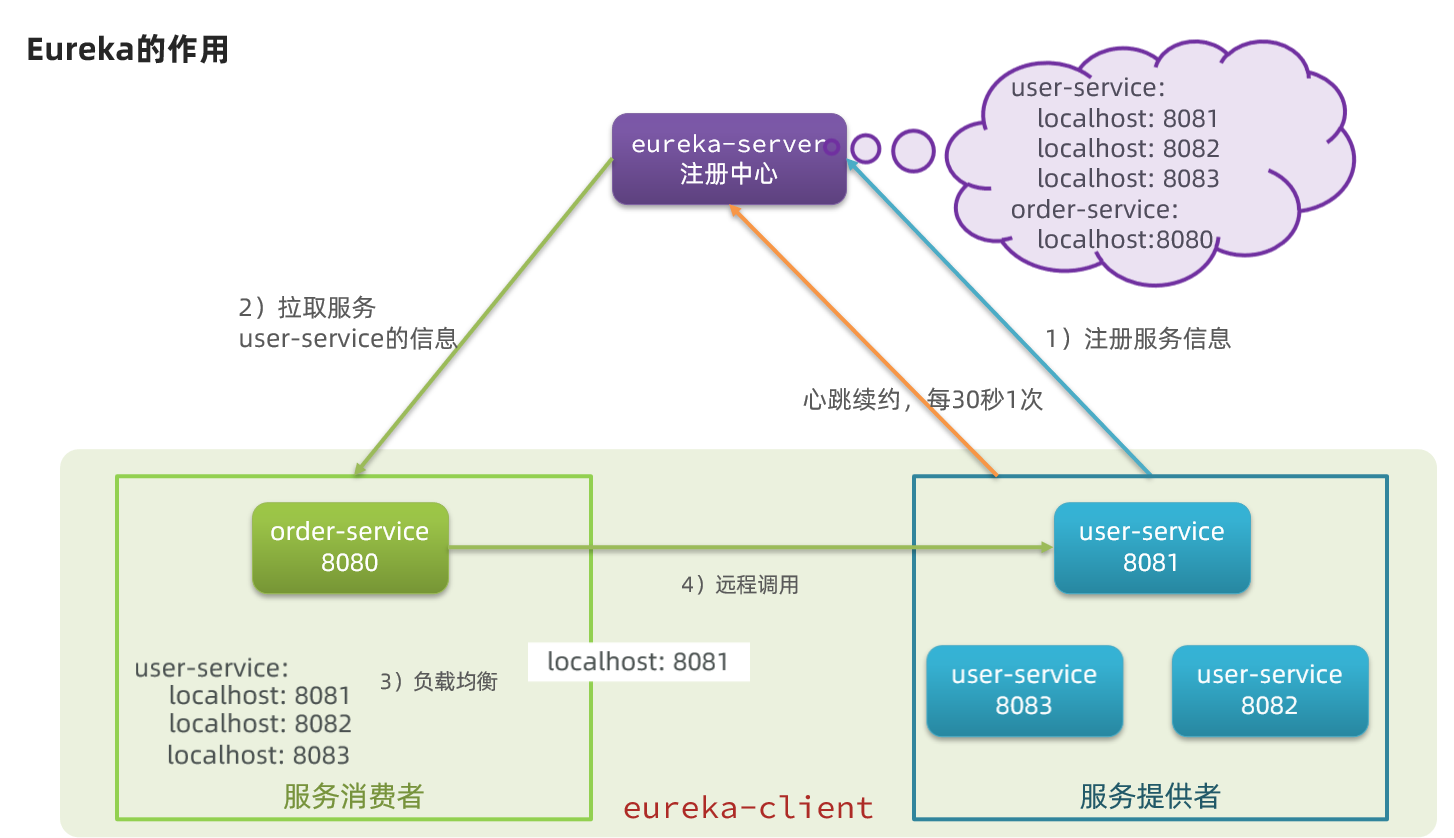
三. Eureka注册中心
提供者与消费者
服务提供者:被其他微服务调用的服务
服务消费者:调用其他微服务的服务
一个服务既可以是提供者,也可以是消费者。
总体流程
Eureka搭建
第一步:引入依赖
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-server</artifactId > </dependency >
第二步:启动类加注解 @EnableEurekaServer
1 2 3 4 5 6 7 @EnableEurekaServer @SpringBootApplication public class EurekaApplication { public static void main (String[] args) { SpringApplication.run(EurekaApplication.class, args); } }
第三步:配置文件application.yml
1 2 3 4 5 6 7 8 9 server: port: 10086 # 服务端口 spring: application: name: eurekaserver # 服务名称 eureka: client: service-url: defaultZone: http:
Eureka服务注册
与上述过程类似,引依赖、配地址和服务名称,要注意依赖选择client,如下所示:
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-netflix-eureka-client</artifactId > </dependency >
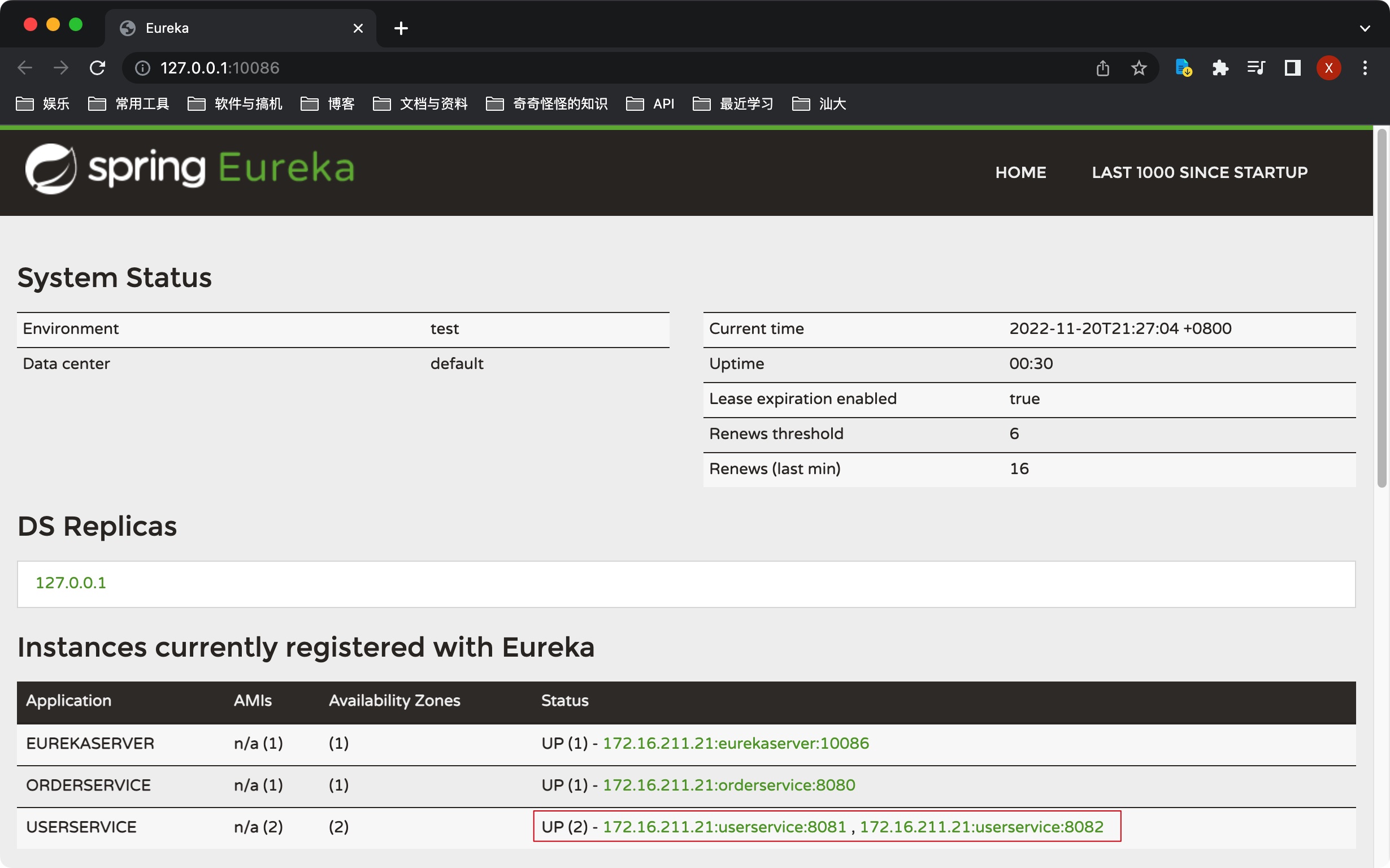
在IDEA中,对已运行的服务右键->Copy Configuration,在VM options中指定新的端口号,例如-Dserver.port=8082,可以将原来的服务复制一份,部署后查看Eureka的注册中心情况。
服务发现
在前面的例子中,orderservice要调用userservice服务,因此我们在orderservice中引入eureka-client的依赖,并且修改请求URL:
1 String url = "http://userservice/user/" + order.getUserId();
然后在启动类中RestTemplate上加@LoadBalanced注解实现负载均衡。
Spring会自动根据服务名为userservice的实例列表,进行负载均衡并请求。
四. Ribbon负载均衡
过程
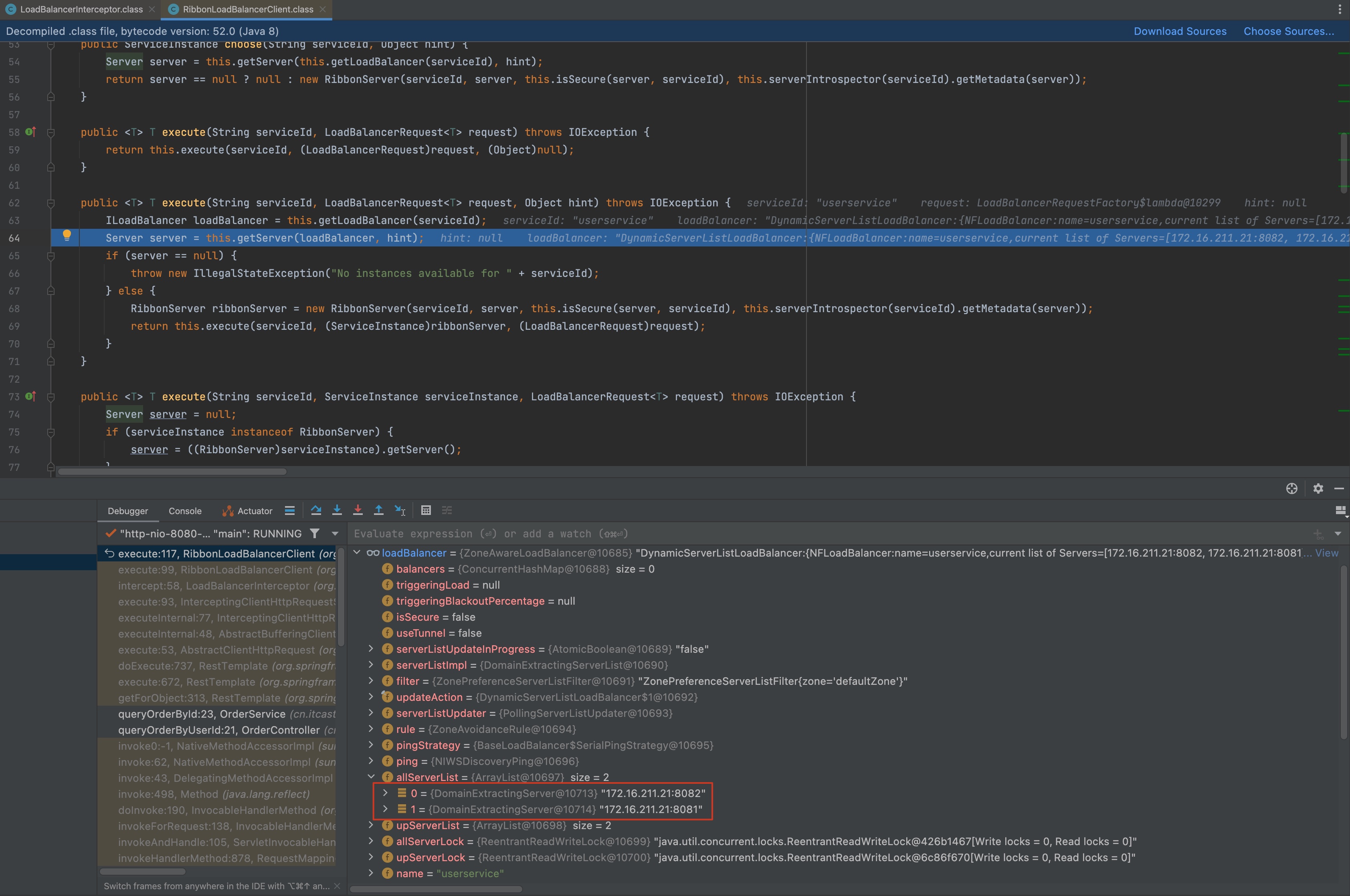
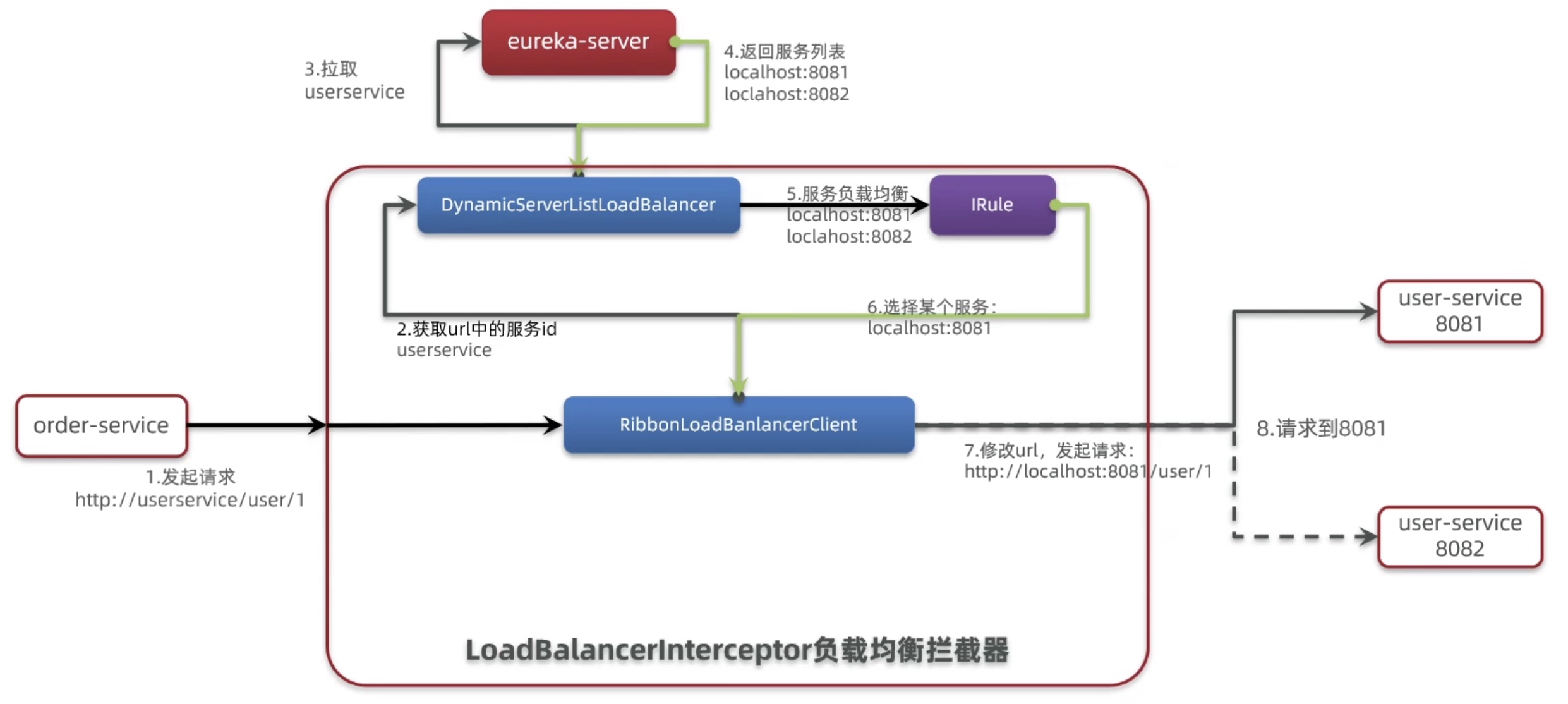
找到LoadBalancerInterceptor.class,跟踪代码,可以找到RibbonLoadBalancerClient.class。
可以看到,里面是先拿到allServerList,里面包含了被调用微服务userservice的服务列表,包括IP地址和端口号。
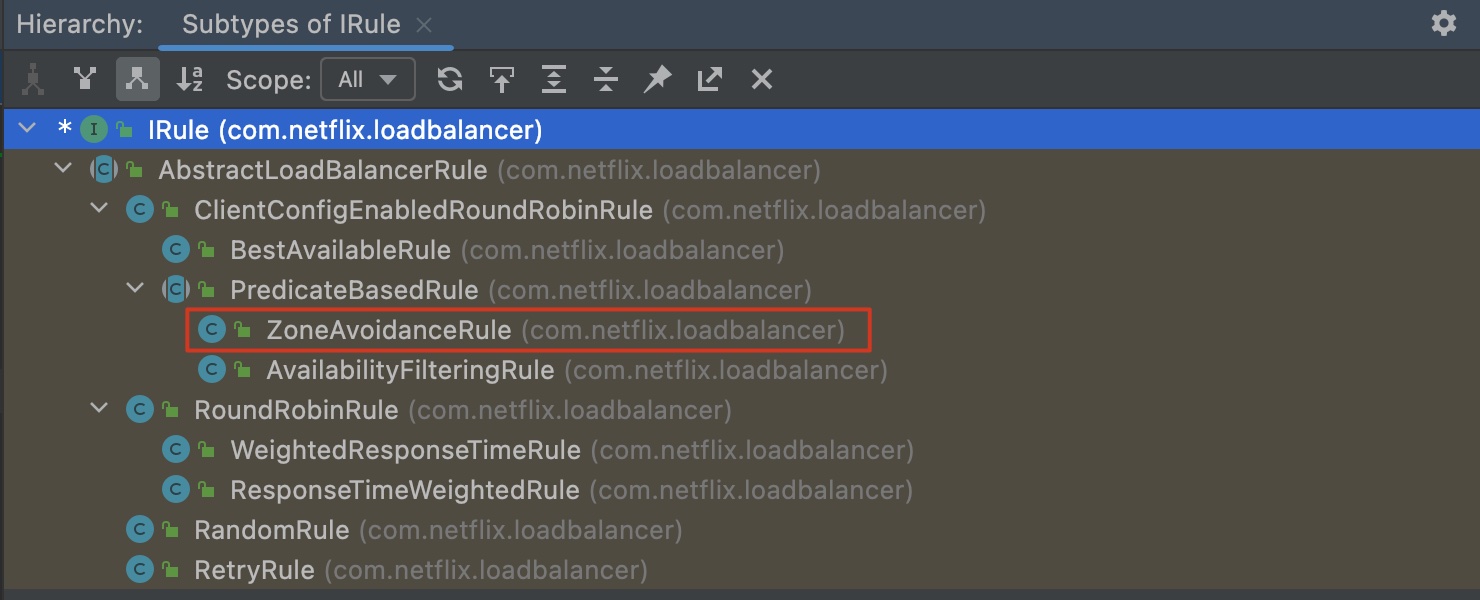
继续跟踪代码,会发现后续之行了一个名为chooseServer的函数,里面调用了Irule接口的实例。
在IDEA中,光标选中Irule接口,然后按快捷键Ctrl+H,就可以看到它的实现。里面的规则包括RoundRobin(轮询)和Random(随机)等。在这次跟踪中,最后发现其采用的是ZoneAvoidanceRule。
总体流程如下图:
规则
上面说到有不同的rule(规则),不同规则的含义如下所示。
内置负载均衡规则类 规则描述
RoundRobinRule
简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。
AvailabilityFilteringRule
对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。
WeightedResponseTimeRule
为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。
ZoneAvoidanceRule 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。
BestAvailableRule
忽略那些短路的服务器,并选择并发数较低的服务器。
RandomRule
随机选择一个可用的服务器。
RetryRule
重试机制的选择逻辑
自定义规则
方案一(全局):在启动类或配置类中注入Irule即可,例如:
1 2 3 4 @Bean public IRule randomRule () { return new RandomRule (); }
方案二(局部):在orderservice的application.yml中配置:
1 2 3 userservice: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
饥饿加载
Ribbon默认懒加载,即第一次访问才去创建LoadBalanceClient。开启饥饿加载,可以在项目启动时就创建,降低第一次的访问耗时。
在上面的例子中,不开启饥饿加载的情况下,第一次访问加载大约要500ms。
开启后,响应时间降到250ms左右,快了一半,但仍比第二次访问的30ms慢很多,这是因为第一次还要加载DispatcherServlet等。
开启饥饿加载需要配置application.yml:
1 2 3 4 5 ribbon: eager-load: enabled: true clients: - userservice
五. Nacos注册中心
5.1 入门
这是阿里巴巴的产品,是SpringCloud中的一个组件,相比Eureka功能更加丰富。
下面是在m1 macOS Docker中安装的过程。
1 2 3 4 5 docker pull zhusaidong/nacos-server-m1:2.0.3 docker run -d -p 8848:8848 --env MODE=standalone --name nacos zhusaidong/nacos-server-m1:2.0.3
然后访问地址:http://localhost:8848/nacos/
账号/密码:nacos/nacos
引入依赖过程
在上面使用了Eureka的情况下,只需修改部分依赖即可。
首先是在父工程的pom文件引入:
1 2 3 4 5 6 7 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-alibaba-dependencies</artifactId > <version > 2.2.6.RELEASE</version > <type > pom</type > <scope > import</scope > </dependency >
然后注释掉子工程原有的eureka依赖,添加nacos客户端依赖:
1 2 3 4 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-discovery</artifactId > </dependency >
application.yml配置文件也要改:
1 2 3 4 spring: cloud: nacos: server-addr: localhost:8848
5.2 服务多级存储模型
分级:服务->集群->实例
微服务互相访问时,应该尽可能访问同集群实例,因为本地访问速度更快。当本集群内不可用时,才访问其它集群。
如果需要设置实例的集群属性,只需要在application.yml中配置spring.cloud.nacos.discovery.cluster-name即可。
实现尽可能同集群调用
例如orderservice在SZ集群,userservice1在SZ集群,userservice2和userservice3在SH集群,那么orderservice应该优先调用userservice1。
需要在orderservice的application.yml中配置负载均衡规则:
1 2 3 userservice: ribbon: NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule
如果把userservice1关闭,这样就造成了跨集群访问,会有警告信息,如下所示:
1 11 -24 14 :29 :15 :475 WARN 18250 --- [io-8080 -exec-10 ] c.alibaba.cloud.nacos.ribbon.NacosRule : A cross-cluster call occurs,name = userservice, clusterName = SH, instance = [Instance{instanceId='172.16.211.21#8082#SZ#DEFAULT_GROUP@@userservice' , ip='172.16.211.21' , port=8082 , weight=1.0 , healthy=true , enabled=true , ephemeral=true , clusterName='SZ' , serviceName='DEFAULT_GROUP@@userservice' , metadata={preserved.register.source=SPRING_CLOUD}}, Instance{instanceId='172.16.211.21#8081#SZ#DEFAULT_GROUP@@userservice' , ip='172.16.211.21' , port=8081 , weight=1.0 , healthy=true , enabled=true , ephemeral=true , clusterName='SZ' , serviceName='DEFAULT_GROUP@@userservice' , metadata={preserved.register.source=SPRING_CLOUD}}]
5.3 权重设置
我们希望性能更好的服务器承担更多用户请求,可以通过Nacos的权重配置来控制访问频率。
在Nacos的控制台中,点击实例列表中的编辑按钮,即可修改权重(默认为1)。
如果需要对服务进行升级,可以先将部分实例权重设为0,然后进行代码更新,用户几乎零感知。
5.4 命名空间
Nacos提供了namespace来实现环境隔离功能。
Nacos中可以有多个namespace
namespace下可以有group、service等
不同namespace之间相互隔离,例如不同namespace的服务互相不可见
需要配置服务的application.yml中的namespace字段:
1 2 3 4 5 6 7 spring: cloud: nacos: server-addr: localhost:8848 discovery: cluster-name: SH namespace: 403cb990-c8be-460a-81d4-c9b8428a4385
5.5 Nacos对比Eureka
非临时实例配置
spring.cloud.nacos.discovery.ephemeral = false
5.6 配置管理
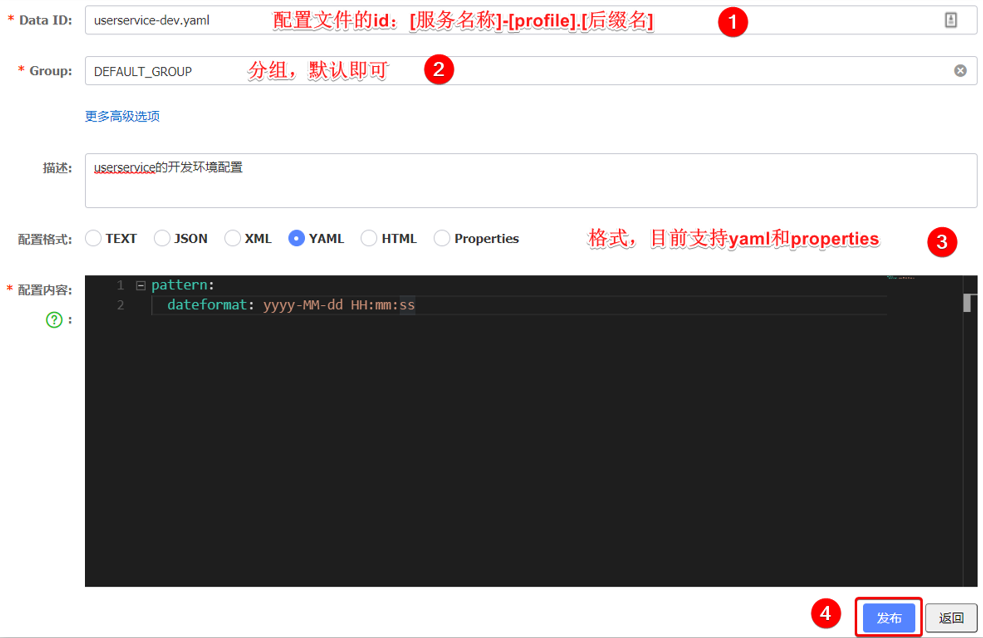
添加
在Nacos的配置管理->配置列表中添加,如下图所示。
在项目中,需要热更新的配置才有必要放到Nacos的配置管理中,如果是数据库地址这种基本不会变的配置,保存在本地的配置文件即可。
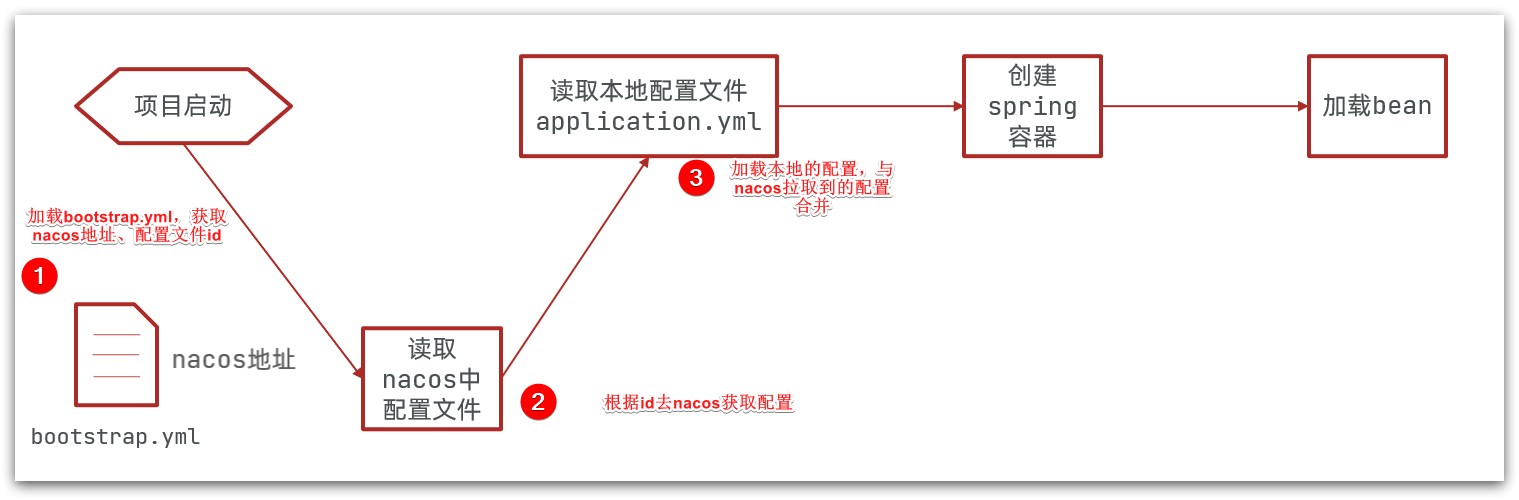
拉取
微服务要结合Nacos和本地application.yml的配置,但是由于Nacos配置文件的读取是在本地配置文件之前的,所以要引入bootstrap.yml配置,它的优先级最高。
首先,在userservice引入依赖:
1 2 3 4 5 <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-config</artifactId > </dependency >
然后新添加bootstrap.yml
1 2 3 4 5 6 7 8 9 10 spring: application: name: userservice profiles: active: dev cloud: nacos: server-addr: localhost:8848 config: file-extension: yaml
然后就会到Nacos中寻找userservice-dev.yaml的配置文件。
然后在Spring中读取Nacos的配置文件详情,观察是否拉取成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Slf4j @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; @Value("${pattern.dateformat}") private String dateformat; @GetMapping("/now") public String now () { return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat)); } }
访问http://localhost:8081/user/now,页面显示2022-11-26 15:45:11。
热更新
方式一:在@Value注入变量所在类上添加@RefreshScope注解
方式二:使用@ConfigurationProperties:
1 2 3 4 5 6 @Data @Component @ConfigurationProperties(prefix = "pattern") public class PatternProperties { private String dateformat; }
然后使用自动注入@Autowired注解。
5.7 Nacos集群搭建
5.7.1 在MySQL数据库nacos中建立表:
注意:一定要把下面SQL语句执行完毕,如果漏了某个部分可能会造成一些问题,建议分步执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 CREATE TABLE `config_info` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (255 ) DEFAULT NULL , `content` longtext NOT NULL COMMENT 'content' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , `app_name` varchar (128 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , `c_desc` varchar (256 ) DEFAULT NULL , `c_use` varchar (64 ) DEFAULT NULL , `effect` varchar (64 ) DEFAULT NULL , `type` varchar (64 ) DEFAULT NULL , `c_schema` text, PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info' ; CREATE TABLE `config_info_aggr` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (255 ) NOT NULL COMMENT 'group_id' , `datum_id` varchar (255 ) NOT NULL COMMENT 'datum_id' , `content` longtext NOT NULL COMMENT '内容' , `gmt_modified` datetime NOT NULL COMMENT '修改时间' , `app_name` varchar (128 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '增加租户字段' ; CREATE TABLE `config_info_beta` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL COMMENT 'content' , `beta_ips` varchar (1024 ) DEFAULT NULL COMMENT 'betaIps' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info_beta' ; CREATE TABLE `config_info_tag` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT 'tenant_id' , `tag_id` varchar (128 ) NOT NULL COMMENT 'tag_id' , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL COMMENT 'content' , `md5` varchar (32 ) DEFAULT NULL COMMENT 'md5' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , `src_user` text COMMENT 'source user' , `src_ip` varchar (50 ) DEFAULT NULL COMMENT 'source ip' , PRIMARY KEY (`id`), UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_info_tag' ; CREATE TABLE `config_tags_relation` ( `id` bigint (20 ) NOT NULL COMMENT 'id' , `tag_name` varchar (128 ) NOT NULL COMMENT 'tag_name' , `tag_type` varchar (64 ) DEFAULT NULL COMMENT 'tag_type' , `data_id` varchar (255 ) NOT NULL COMMENT 'data_id' , `group_id` varchar (128 ) NOT NULL COMMENT 'group_id' , `tenant_id` varchar (128 ) DEFAULT '' COMMENT 'tenant_id' , `nid` bigint (20 ) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`nid`), UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'config_tag_relation' ; CREATE TABLE `group_capacity` ( `id` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID' , `group_id` varchar (128 ) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群' , `quota` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值' , `usage` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '使用量' , `max_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值' , `max_aggr_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值' , `max_aggr_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值' , `max_history_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_group_id` (`group_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '集群、各Group容量信息表' ; CREATE TABLE `his_config_info` ( `id` bigint (64 ) unsigned NOT NULL , `nid` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT, `data_id` varchar (255 ) NOT NULL , `group_id` varchar (128 ) NOT NULL , `app_name` varchar (128 ) DEFAULT NULL COMMENT 'app_name' , `content` longtext NOT NULL , `md5` varchar (32 ) DEFAULT NULL , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP , `src_user` text, `src_ip` varchar (50 ) DEFAULT NULL , `op_type` char (10 ) DEFAULT NULL , `tenant_id` varchar (128 ) DEFAULT '' COMMENT '租户字段' , PRIMARY KEY (`nid`), KEY `idx_gmt_create` (`gmt_create`), KEY `idx_gmt_modified` (`gmt_modified`), KEY `idx_did` (`data_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '多租户改造' ; CREATE TABLE `tenant_capacity` ( `id` bigint (20 ) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID' , `tenant_id` varchar (128 ) NOT NULL DEFAULT '' COMMENT 'Tenant ID' , `quota` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值' , `usage` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '使用量' , `max_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值' , `max_aggr_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数' , `max_aggr_size` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值' , `max_history_count` int (10 ) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量' , `gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , `gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= '租户容量信息表' ; CREATE TABLE `tenant_info` ( `id` bigint (20 ) NOT NULL AUTO_INCREMENT COMMENT 'id' , `kp` varchar (128 ) NOT NULL COMMENT 'kp' , `tenant_id` varchar (128 ) default '' COMMENT 'tenant_id' , `tenant_name` varchar (128 ) default '' COMMENT 'tenant_name' , `tenant_desc` varchar (256 ) DEFAULT NULL COMMENT 'tenant_desc' , `create_source` varchar (32 ) DEFAULT NULL COMMENT 'create_source' , `gmt_create` bigint (20 ) NOT NULL COMMENT '创建时间' , `gmt_modified` bigint (20 ) NOT NULL COMMENT '修改时间' , PRIMARY KEY (`id`), UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`), KEY `idx_tenant_id` (`tenant_id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8 COLLATE = utf8_bin COMMENT= 'tenant_info' ; CREATE TABLE `users` ( `username` varchar (50 ) NOT NULL PRIMARY KEY, `password` varchar (500 ) NOT NULL , `enabled` boolean NOT NULL ); CREATE TABLE `roles` ( `username` varchar (50 ) NOT NULL , `role` varchar (50 ) NOT NULL , UNIQUE INDEX `idx_user_role` (`username` ASC , `role` ASC ) USING BTREE ); CREATE TABLE `permissions` ( `role` varchar (6 ) NOT NULL , `resource` varchar (255 ) NOT NULL , `action` varchar (8 ) NOT NULL , UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE )ENGINE= InnoDB DEFAULT CHARSET= utf8; INSERT INTO users (username, password, enabled) VALUES ('nacos' , '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu' , TRUE );INSERT INTO roles (username, role) VALUES ('nacos' , 'ROLE_ADMIN' );
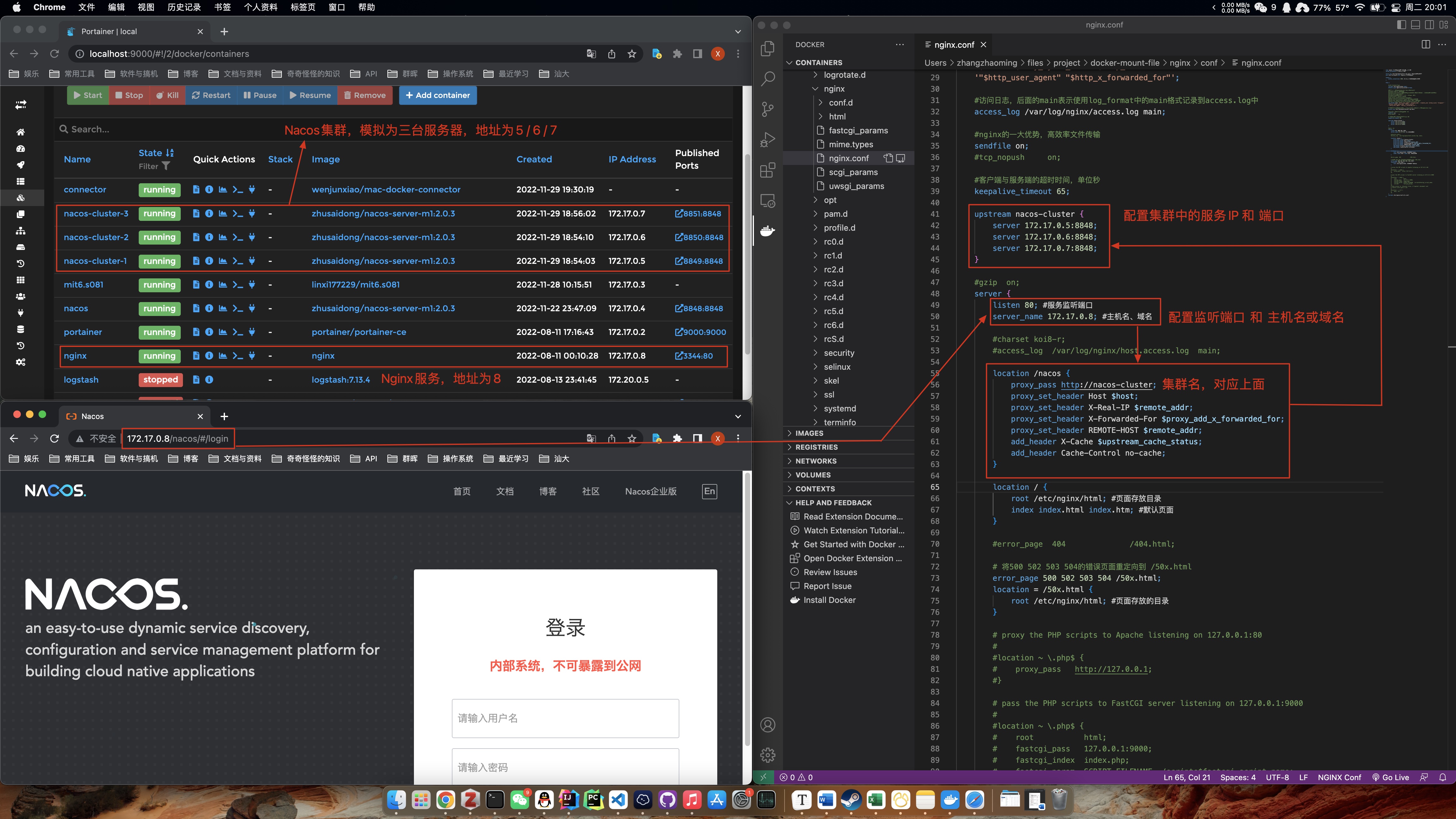
5.7.2 使用Docker部署Nacos集群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 docker run -d \ -e PREFER_HOST_MODE=hostname \ -e MODE=cluster \ -e NACOS_APPLICATION_PORT=8848 \ -e NACOS_SERVERS="172.17.0.5:8848 172.17.0.6:8848 172.17.0.7:8848" \ -e SPRING_DATASOURCE_PLATFORM=mysql \ -e MYSQL_SERVICE_HOST=175.178.56.73 \ -e MYSQL_SERVICE_PORT=3306 \ -e MYSQL_SERVICE_USER=root \ -e MYSQL_SERVICE_PASSWORD=pass123456 \ -e MYSQL_SERVICE_DB_NAME=nacos \ -e NACOS_SERVER_IP=172.17.0.5 \ -p 8849:8848 \ --name nacos-cluster-1 zhusaidong/nacos-server-m1:2.0.3 docker run -d \ -e PREFER_HOST_MODE=hostname \ -e MODE=cluster \ -e NACOS_APPLICATION_PORT=8848 \ -e NACOS_SERVERS="172.17.0.5:8848 172.17.0.6:8848 172.17.0.7:8848" \ -e SPRING_DATASOURCE_PLATFORM=mysql \ -e MYSQL_SERVICE_HOST=175.178.56.73 \ -e MYSQL_SERVICE_PORT=3306 \ -e MYSQL_SERVICE_USER=root \ -e MYSQL_SERVICE_PASSWORD=pass123456 \ -e MYSQL_SERVICE_DB_NAME=nacos \ -e NACOS_SERVER_IP=172.17.0.6 \ -p 8850:8848 \ --name nacos-cluster-2 zhusaidong/nacos-server-m1:2.0.3 docker run -d \ -e PREFER_HOST_MODE=hostname \ -e MODE=cluster \ -e NACOS_APPLICATION_PORT=8848 \ -e NACOS_SERVERS="172.17.0.5:8848 172.17.0.6:8848 172.17.0.7:8848" \ -e SPRING_DATASOURCE_PLATFORM=mysql \ -e MYSQL_SERVICE_HOST=175.178.56.73 \ -e MYSQL_SERVICE_PORT=3306 \ -e MYSQL_SERVICE_USER=root \ -e MYSQL_SERVICE_PASSWORD=pass123456 \ -e MYSQL_SERVICE_DB_NAME=nacos \ -e NACOS_SERVER_IP=172.17.0.7 \ -p 8851:8848 \ --name nacos-cluster-3 zhusaidong/nacos-server-m1:2.0.3
需要自行配集群置IP和MySQL等相关信息,如果需要固定Docker容器的IP,就要先在Docker中创建自定义网络,然后启动时使用--net指定网络,--ip指定IP地址。
实测使用MySQL8版本的数据库,Nacos无法启动,换成云服务器的MySQL5.7版本可以正常连接,目前还不清楚是什么原因。Docker容器中的Nacos配置文件在/home/nacos/conf/文件夹。
5.7.4 配置Nginx进行负载均衡(conf文件)
注意这里有个坑,Docker For Mac在宿主机上无法通过IP地址去访问容器,只能通过localhost访问,解决方法详见 https://www.515code.com/posts/n1u7t6h5/ 第六部分。
然后要配置Nginx的conf文件(Nginx也推荐用Docker部署,容器中配置文件在/etc/nginx/nginx.conf):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 upstream nacos-cluster { server 172.17.0.5:8848 ; server 172.17.0.6:8848 ; server 172.17.0.7:8848 ; } location /nacos { proxy_pass http://nacos-cluster; proxy_set_header Host $host ; proxy_set_header X-Real-IP $remote_addr ; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; proxy_set_header REMOTE-HOST $remote_addr ; add_header X-Cache $upstream_cache_status ; add_header Cache-Control no -cache; }
在游览器访问172.17.0.8/nacos即可,在配置文件中填写Nacos地址为172.17.0.8:80,负载均衡实现如下图所示:
在Nacos集群的配置列表中新增配置,然后查看数据库,可以看到config_info表新增了一条记录。说明相关配置会被持久化到MySQL数据库中。
六. Feign远程调用
6.1 替代RestTemplate
RestTemplate调用问题:代码可读性差,参数复杂且URL难维护。
Feign是一个声明式的HTTP客户端,官方地址:https://github.com/OpenFeign/feign
它可以解决上述提到的问题。
STEP1:首先,在orderservice中引入依赖
1 2 3 4 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-openfeign</artifactId > </dependency >
STEP2:在启动类添加@EnableFeignClients注解
STEP3:创建一个调用接口
1 2 3 4 5 6 7 @FeignClient("userservice") public interface UserClient { @GetMapping("/user/{id}") User findById (@PathVariable("id") Long id) ; }
STEP4:编写业务代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private UserClient userClient; public Order queryOrderById (Long orderId) { Order order = orderMapper.findById(orderId); User user = userClient.findById(order.getUserId()); order.setUser(user); return order; } }
对比一下之前的代码,使用Feign方式更简洁,编程体验也更统一。
6.2 自定义配置
类型
作用
说明
feign.Logger.Level
修改日志级别
包含四种不同的级别:NONE、BASIC、HEADERS、FULL
feign.codec.Decoder
响应结果的解析器
http远程调用的结果做解析,例如解析JSON字符串为Java对象
feign.codec.Encoder
请求参数编码
将请求参数编码,便于通过http请求发送
feign. Contract
支持的注解格式
默认是SpringMVC的注解
feign. Retryer
失败重试机制
请求失败的重试机制,默认是没有,不过会使用Ribbon的重试
方式一:配置文件方式
全局
1 2 3 4 5 feign: client: config: default: loggerLevel: FULL
针对服务
1 2 3 4 5 feign: client: config: userservice: loggerLevel: FULL
方式二:代码方式
先定义一个Bean对象:
1 2 3 4 5 6 public class DefaultFeignConfiguration { @Bean public Logger.Level feignLogLevel () { return Logger.Level.BASIC; } }
全局生效 ,需要在启动类注解中添加:
1 @EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)
局部生效 ,需要找到对应的Client,例如:
1 @FeignClient(value = "userservice", configuration = DefaultFeignConfiguration.class)
6.3 性能优化
Feign底层发起HTTP请求,依赖于其它的框架,底层客户端实现包括:
URLConnection:默认实现,不支持连接池
Apache HttpClient :支持连接池
OKHttp:支持连接池
因此,要提高Feign的性能,最重要的一点就是使用连接池。同时,建议使用BASIC日志级别(太多日志影响性能)。
使用 Apache HttpClient
1)引入依赖
1 2 3 4 <dependency > <groupId > io.github.openfeign</groupId > <artifactId > feign-httpclient</artifactId > </dependency >
2)配置连接池
1 2 3 4 5 feign: httpclient: enabled: true max-connections: 200 max-connections-per-route: 50
除了上面的参数,还有很多参数可以配置,例如存活时间等。
6.4 最佳实践
先来看看原来的代码。
Feign客户端:
1 2 3 4 5 @FeignClient("userservice") public interface UserClient { @GetMapping("/user/{id}") User findById (@PathVariable("id") Long id) ; }
被调用的服务Controller:
1 2 3 4 @GetMapping("/user/{id}") public User queryById (@PathVariable("id") Long id) { return userservice.queryById(id); }
有没有什么方法简化代码呢?答案就是:继承或抽取(根据需求选择,没有十全十美的方案)。
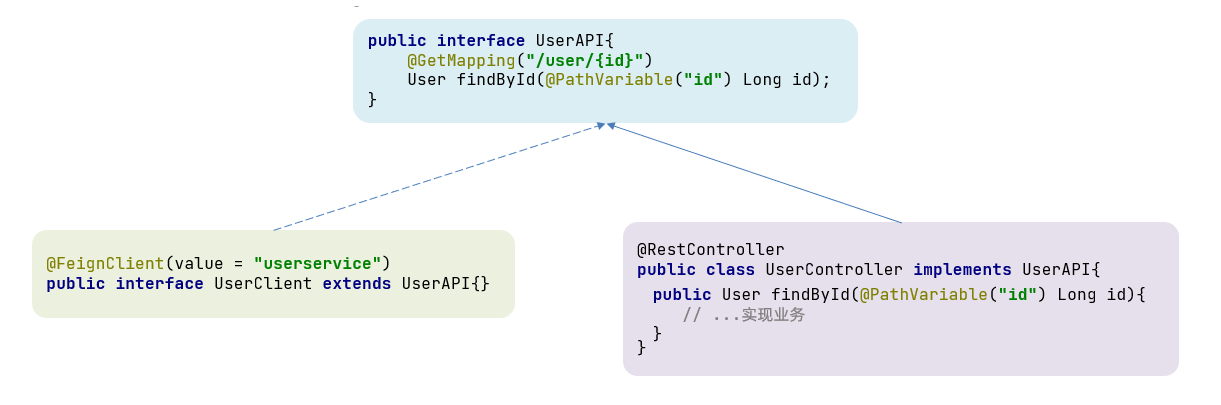
方式一(继承):给消费者的FeignClient和提供者的controller定义统一的父接口作为标准。
优点:可以规范接口,实现面向契约编程和代码共享 。
缺点:会造成服务提供者和消费者的代码紧耦合 ,且参数列表的注解不会被继承,Controller需要再次声明方法、参数列表和注解。
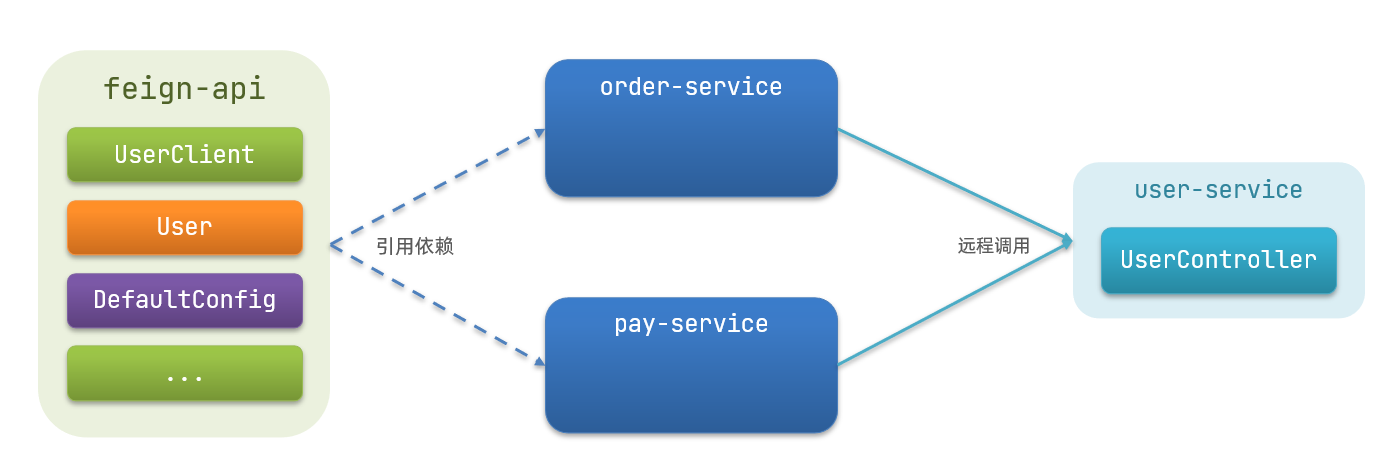
方式二(抽取):将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用
例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。
优点:不用重复编写UserClient,降低代码量 。
缺点:假设只需要用到userservice的部分接口,但是使用这种方式会将接口全部引入,造成冗余 。
七. 网关
7.1 概述
不是所有人都可以调用微服务,我们需要网关(Gateway)作为微服务的统一入口,它的功能包括身份认证、权限校验、服务路由、负载均衡和请求限流等 。
在SpringCloud中,网关的实现有两种:SpringCloudGateway 和Zuul 。
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
7.2 搭建
STEP1:创建一个新的module,引入依赖:
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.springframework.cloud</groupId > <artifactId > spring-cloud-starter-gateway</artifactId > </dependency > <dependency > <groupId > com.alibaba.cloud</groupId > <artifactId > spring-cloud-starter-alibaba-nacos-discovery</artifactId > </dependency >
STEP2:编写启动类:
1 2 3 4 5 6 @SpringBootApplication public class GatewayApplication { public static void main (String[] args) { SpringApplication.run(GatewayApplication.class, args); } }
STEP3:配置网关举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 server: port: 10010 spring: application: name: gateway cloud: nacos: server-addr: 172.20 .0 .2 :80 discovery: namespace: 5b812fef-b156-4783-be29-c6ff749e38cd gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** - id: order-service uri: lb://orderservice predicates: - Path=/order/**
访问 localhost:10010/user/1 即可查询id为1的用户信息,访问 localhost:10010/order/101 即可查询id为101的订单信息,实现了路由,整个流程如下图所示。
7.3 断言工厂
在配置文件中写的断言规则是字符串,会被Predicate Factory读取和处理。除了Path匹配路径,还有很多个参数可以配置:
名称 说明 示例
After
是某个时间点后的请求
- After=2037-01-20T17:42:47.789-07:00[America/Denver]
Before
是某个时间点之前的请求
- Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai]
Between
是某两个时间点之前的请求
- Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver]
Cookie
请求必须包含某些cookie
- Cookie=chocolate, ch.p
Header
请求必须包含某些header
- Header=X-Request-Id, \d+
Host
请求必须是访问某个host(域名)
- Host=**.somehost.org,**.anotherhost.org
Method
请求方式必须是指定方式
- Method=GET,POST
Path
请求路径必须符合指定规则
- Path=/red/{segment},/blue/**
Query
请求参数必须包含指定参数
- Query=name, Jack 或者 - Query=name
RemoteAddr
请求者的ip必须是指定范围
- RemoteAddr=192.168.1.1/24
Weight
权重处理
7.4 路由过滤器和默认过滤器
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理。
种类:https://docs.spring.io/spring-cloud-gateway/docs/current/reference/html/#gatewayfilter-factories
以 AddRequestHeader 为例
目的:给所有进入userservice的请求加一个请求头。
在application.yml中配置如下:
1 2 3 4 5 6 7 8 9 10 spring: cloud: gateway: routes: - id: user-service uri: lb://userservice predicates: - Path=/user/** filters: - AddRequestHeader=Truth, 515code is freaking awesome!
然后去userservice的controller中打印一下:
1 2 3 4 5 @GetMapping("/{id}") public User queryById (@PathVariable("id") Long id, @RequestHeader(value = "Truth", required = false) String truth) { System.out.printf("truth: " + truth); return userService.queryById(id); }
默认过滤器(全局,配置实现)
配置default-filters字段即可,注意与routes同级。
7.5 全局过滤器(代码实现)
与上面提到的GatewayFilter作用一样,区别在于GatewayFilter使用配置文件来定义,处理逻辑固定。
而GlobalFilter的逻辑需要代码实现,方式是实现GlobalFilter接口。
1 2 3 4 5 6 7 8 9 10 public interface GlobalFilter { Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) ; }
自定义:以实现Authorization过滤器为例,检查该字段是否为admin,是则通过,不是则过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Component public class AuthorizeFilter implements GlobalFilter , Ordered { @Override public Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); MultiValueMap<String, String> params = request.getQueryParams(); String auth = params.getFirst("Authorization" ); if ("admin" .equals(auth)) { return chain.filter(exchange); } exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED); return exchange.getResponse().setComplete(); } @Override public int getOrder () { return -1 ; } }
这时候访问http://localhost:10010/order/101,页面会报401错误。访问http://localhost:10010/order/101?Authorization=admin则正常。
实际开发中,业务逻辑肯定会比上面的例子更复杂,例如读取Cookie/Session等。
7.6 过滤器执行顺序
之前已经学过,进入网关后会有三类过滤器:路由过滤器、默认过滤器(DefaultFilter)和全局过滤器(GlobalFilter) 。
请求路由后,会将当前路由过滤器和默认过滤器、全局过滤器合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:
路由 <—> 默认过滤器 <—> 路由过滤器 <—> 全局过滤器 <—> 微服务
排序的规则:
每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前 。
GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
当过滤器的order值一样时,会按照 默认过滤器 > 路由过滤器 > 全局过滤器 的顺序执行。
7.7 跨域问题
编写一个跨域请求来测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, initial-scale=1.0" > <meta http-equiv ="X-UA-Compatible" content ="ie=edge" > <title > Document</title > </head > <body > 这是跨域请求测试,请查看控制台。 </body > <script src ="https://unpkg.com/axios/dist/axios.min.js" > </script > <script > axios.get ("http://localhost:10010/user/1?Authorization=admin" ) .then (resp =>console .log (resp.data )) .catch (err =>console .log (err)) </script > </html >
进入控制台,可以查看到错误信息:index.html:1 Access to XMLHttpRequest at 'http://localhost:10010/user/1?Authorization=admin' from origin 'http://127.0.0.1:5500' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
采用CORS方案解决,通过配置即可实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 spring: cloud: gateway: globalcors: add-to-simple-url-handler-mapping: true corsConfigurations: '[/**]' : allowedOrigins: - "http://127.0.0.1:5500" allowedMethods: - "GET" - "POST" - "DELETE" - "PUT" - "OPTIONS" allowedHeaders: "*" allowCredentials: true maxAge: 360000


 wechat
wechat alipay
alipay